There is a particular kind of Monday morning that every MSP Managing Director recognises, even if they are not the one opening the report. The weekend SLA summary lands, someone on the leadership team scans the failure count, grimaces, and goes looking for what happened. A P2 sat unassigned over Saturday because the engineer who picked it up went offline and nobody reassigned it. A connectivity ticket got miscategorised at intake and sat in the wrong queue for four hours. A VIP client’s request arrived during the lunchtime handover window and fell through the gap. Each one feels like a one-off incident, each one gets its own little post-mortem analysis, and each one happens again next month.
Before you reach the operational mechanics, consider what that looks like on a board report. If your mid-market contracts average £38,000 annually and service reliability is driving client exits, three missed commitments in a quarter can lead to margin erosion. The data that explains those failures already exists in your PSA, but the question is whether anyone reads it before the renewal goes cold.
Most service desks treat each contractual miss as an event that requires a discrete explanation, when the data sitting in ConnectWise Manage or Autotask would show them that the same categories, the same engineers, and the same hours are responsible for the majority of their SLA exposure. Research published in the International Journal of Information Management Data Insights found that incident category was one of the key factors associated with SLA breach risk, with certain categories showing significantly higher likelihood of breach.
This stems from a structural issue, that MSP SLA breach patterns remain entirely readable before the exposure happens.
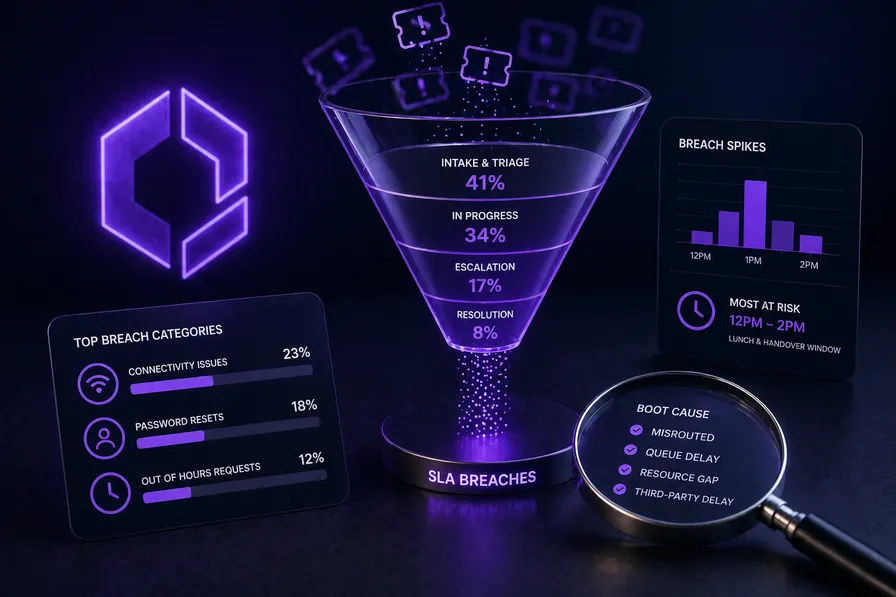
Start with ticket category and the failure rate per category over a rolling 90-day window. Most PSAs will surface this in a custom report if you build it, and almost nobody does. What you will typically find is that two or three ticket types account for a disproportionate share of total SLA misses. Connectivity issues are a common culprit, partly because they often arrive with vague initial descriptions that make priority assignment difficult at intake, and partly because they frequently require third-party escalation that nobody has a clear ownership process for. Password resets and account lockouts are another recurring issue because they tend to cluster at predictable times and swamp first-line capacity in ways that delay everything else sitting in the same queue.
Category data tells you which ticket types are failing. It does not tell you where in the lifecycle the time is being lost, and that distinction matters.
There is a meaningful difference between a missed commitment caused by slow first response and one caused by slow resolution after the work has actually started. The former is almost always an intake, assignment, or queue capacity problem. The latter is usually a knowledge, escalation, or third-party dependency problem. Your remediation for each is completely different, and conflating them in your post-mortem is why you keep having the same internal review.
The time-of-day dimension is where most service desks leave real insight on the table. Pull your failure timestamps and overlay them against your staffing schedule. The lunchtime window, typically noon to 2pm, shows up as an exposure spike at an uncomfortable number of MSPs, as does the 30 to 45 minutes either side of a shift handover. These are entirely predictable periods of reduced effective capacity, and tickets that arrive in those windows are structurally more likely to miss SLA targets because the human bandwidth to triage and assign them quickly is operating at reduced levels. If your SLA response targets are four hours for a P2 and a ticket arrives at 12:45pm on a Friday before a bank holiday weekend, you have a coverage model that was designed without that scenario in mind.
Queue assignment is the third variable that tends to get ignored until it becomes a client-relationship problem. Among the MSPs we work with, queues correctly staffed at 9am can become critically overloaded by 11am if intake volume spikes and no automatic load-balancing or escalation threshold is configured. In Autotask, queue depth thresholds can be used to trigger notifications or reassignment rules. In ConnectWise, workflow rules can redistribute tickets when a board reaches a configured volume. Regardless of whether your PSA supports this natively or requires a workaround, queue depth needs to be a live operational metric: one you monitor continuously rather than review in a weekly report after the damage is done.
| PSA Platform | Native Queue Depth Alerting | Workflow-Based Redistribution | Requires Configuration |
|---|---|---|---|
| ConnectWise Manage | No | Yes | Yes |
| Autotask | Yes (threshold alerts) | Partial | Yes |
| HaloPSA | Yes | Yes | Minimal |
| Freshservice | Yes | Yes | Minimal |
CompTIA’s research portal tracks sector-wide data on client retention and service reliability. The consistent finding across their State of the Channel reporting is that service reliability ranks among the top reasons clients leave MSPs, contributing to a meaningful share of the sector’s annual churn. A client who has experienced three missed commitments in a quarter rarely phones to complain formally. Instead, they quietly start taking calls from your competitors. By the time you notice the renewal conversation has gone cold and the decision has already been made.
The financial structure of that problem is straightforward. If mid-market UK contracts average £38,000 annually and your churn rate sits at 12%, a portion of that exits quietly and directly because of service delivery failure. The operational data that would have predicted those exits was available months earlier.
The practical starting point is a 90-day audit structured around three questions:
The answers to those three questions, pulled from data that already exists in your PSA, will identify the structural causes of the majority of your SLA exposure. They will also give you a defensible, specific brief for whatever operational changes you decide to make. That might mean adjusting intake categorisation rules, changing shift overlap windows, or configuring queue depth alerts.
What tends to happen when MSPs run this audit for the first time is a mixture of validation and discomfort. Validation because the failure modes confirm what the senior service desk engineers already suspected. Discomfort because those signals have been sitting in the data for months, visible to anyone who looked, while the team was conducting individual post-mortems on what were, in fact, the same systemic failure repeating in slightly different wrappers.
The IT Nation research from ConnectWise consistently shows that MSPs investing in proactive monitoring and structured operational reviews reduce SLA exposure materially within the first two quarters of implementation. The question is how many of them were already visible in the data the week before they happened, and how many more Mondays you spend explaining a structure you could have closed six months ago.
Kevin Wright
Co-founder & CEO, DaemonLayer
Kevin built and exited an IT services business before working in M&A and then as Operations Director at an MSP. He holds an MBA from the University of Manchester. He founded DaemonLayer to fix the coordination problems he watched erode engineer capacity firsthand.
Connect on LinkedIn →